CVE-2022-0847(Dirty Pipe) Remake
本文最后更新于:2024年3月22日 早上
0x00:写在一切之前
Dirty系列第二弹
因为该漏洞发现在对管道写入数据后,读取完毕后未清空pipe_buffer->flags,造成越权写入只读文件
和Dirty Cow很像,因此被冠以Dirty Pipe的称呼
但是和Dirty Cow需要线程竞争相比,Dirty Pipe稳定许多
PS:下文所有源码的版本为 5.8
0x01:信息收集
NVD - cve-2022-0847 (nist.gov)
影响版本:

0x02:前置知识
何为导管🤔
何为管道?好问题,所谓管道,就是连接一个写进程与一个读进程,用于两进程间通信的共享文件,又称pipe文件
向管道(共享文件)提供输入的发送进程(即写进程),以字符流形式将大量的数据送入管道;而接收管道输出的接收进程(即读进程),可从管道中接收数据。由于发送进程和接收进程是利用管道进行通信的,故又称管道通信。
为了协调双方的通信,管道通信机制必须提供以下3 方面的协调能力。
- 互斥。当一个进程正在对
pipe进行读/写操作时,另一个进程必须等待。 - 同步。当写(输入)进程把一定数量(如4KB)数据写入 pipe 后,便去睡眠等待,直到读(输出)进程取走数据后,再把它唤醒。当读进程读到一空
pipe时,也应睡眠等待,直至写进程将数据写入管道后,才将它唤醒。 - 对方是否存在。只有确定对方已存在时,才能进行通信。
pipe の 调用链
接下来就来看看pipe的实现过程
1 | |
do_pipe2
pipe和pipe2都是系统调用,都是do_pipe2的套娃,不同的是,pipe2能自己指定flags
1 | |
1 | |
__do_pipe_flags
1 | |
create_pipe_files
1 | |
get_pipe_inode
1 | |
alloc_pipe_info
1 | |
pipe_inode_info
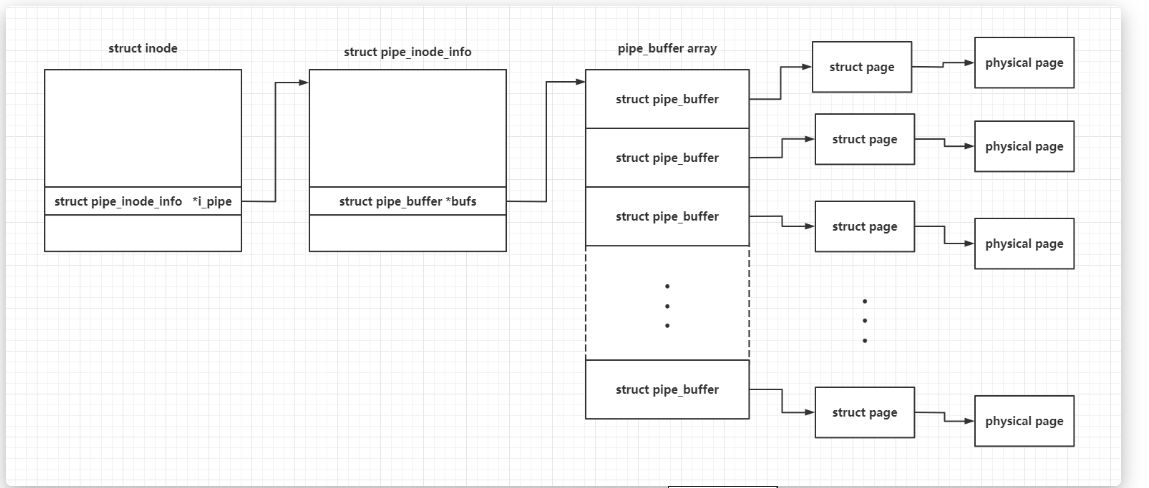
管道的实质是由一个 pipe_inode_info 结构体来管理的,其pipe_buffer类似于循环队列。在这个循环队列中,管道的写入操作是向队列头部添加数据(即往队列尾部移动),而读取操作则是从队列尾部获取数据(即从队列头部移动)。在管道的 pipe_inode_info 结构体中,head 成员表示队列头的索引,tail 成员表示队列尾的索引,头进尾出
1 | |
pipe_buffer
1 | |
pipe的大体结构图如下所示(图来自A3👴的blog)
pipeの函数表
经过如下调用链
1 | |
1 | |
pipefifo_ops
1 | |
重点关注读写操作
pipe_read
从pipe中读取数据,会调用到pipe_read
一个接一个的读取buffer中的数据
1 | |
pipe_write
向pipe中写入,会调用到pipe_write
首先,如果上一个buffer中有剩余空间,并且此buffer的flag是PIPE_BUF_FLAG_CAN_MERGE,会先将此buffer写满
若还有多的数据,会申请新的buffer,将flag设置为PIPE_BUF_FLAG_CAN_MERGE,继续写入
由此可见,PIPE_BUF_FLAG_CAN_MERGE决定了buffer有无写入权限
1 | |
何为splice
一般来说,想要把一个文件的数据拷贝到另一个文件中,常规思路便是打开文件1,复制到用户空间,写入文件2
但这样用户空间和内核空间之间要进行多次用户拷贝,存在客观的开销
所以这时候便要提到splice这个用于在两个文件描述符之间移动数据的系统调用啦
splice 函数是在 Unix/Linux 系统中用于在两个文件描述符之间移动数据的系统调用之一。它通常用于优化数据传输,特别是在文件和管道之间进行零拷贝传输。
1 | |
PS:将fd_in传递到文件描述符fd_out,其中文件描述符之一必须引用管道,对于fd_in来说,若其是一个管道文件描述符,则off_in必须被设置为NULL,若它不是一个管道描述符,则off_in表示从输入数据流的何处开始读入数据,此时,其被设置为NULL,则说明从输入数据的当前偏移位置读入。否则off_in指出具体的偏移位置。以上对于fd_out和off_out同样适用,只不过其用于输出数据流。
splice & pipe
针对上述情况,我们只许创建一个管道,然后通过两次splice便能完成两个文件间的数据拷贝
大概样例如下所示
1 | |
无需进行内核空间和用户空间的拷贝,直接在内核完成一条龙服务
do_splice
根据管道->管道、文件->管道、文件->管道,分为三个分支
1 | |
管道->管道
并不是很重要,就放一边吧😋
splice_pipe_to_pipe
1 | |
文件->管道
do_splice_to
在 do_splice_to 中最终会调用到内核文件结构体函数表的 splice_read 指针,对于不同的文件系统而言该函数指针不同,以 ext4 文件系统为例,查表 ext4_file_operations,对应调用的函数应为 generic_file_splice_read
1 | |
generic_file_splice_read
1 | |
在ext4文件系统中,read_iter其实为shmem_file_read_iter,这B函数调用链有点小长,贴个调用链先
1 | |
copy_page_to_iter_pipe
最终在 copy_page_to_iter_pipe() 中,将对应的 pipe_buffer->page 设为文件映射的页面集的对应页框,将页框引用计数 + 1(get_page()),这样就完成了一个从文件读取数据到管道的过程,因为是直接建立页面的映射,所以每次操作后都会将 head +1
1 | |
PS:此处并没有对pipe_buffer->flags的设置操作
管道->文件
do_splice_from
do_splice_from 最终会根据所操作的文件的属性调用相应的内核文件结构中的 splice_write() 函数指针。
1 | |
iter_file_splice_write
在ext4文件系统中,这个函数指针是iter_file_splice_write,最终会调用如下函数
1 | |
0x03:漏洞分析
我们现在知道以下几点
- PIPE_BUF_FLAG_CAN_MERGE是
pipe_buffer->page是否能写入的标志 pipe_write中会将pipe_buffer->flags设置成PIPE_BUF_FLAG_CAN_MERGEpipe_read中读取完成后free这些page并不会把flags置0- 从文件复制到管道中
copy_page_to_iter_pipe中get_page不会重新设置flags,因此此时pipe_buffer指向的page是目标文件映射的page,pipe_buffer->flags&& PIPE_BUF_FLAG_CAN_MERGE ==true,表示此时对这个page拥有写入权限了。这就意味着如果我们打开的是一个只有只读权限的文件,现在可以越权写入
于是有了这样一个思路
- step Ⅰ:创建一个
pipe - step Ⅱ:把
pipe写满,使所有pipe_buffer->flags都被设置上PIPE_BUF_FLAG_CAN_MERGE - step Ⅲ:读取
pipe中的所有数据,清空pipe - step Ⅳ:打开目标文件,利用
splice将内容从文件拷贝到管道,此时pipe_buffer->page为文件在内存中的映射页框,pipe_buffer->flags保留有之前设置的PIPE_BUF_FLAG_CAN_MERGE,此时在管道中对该文件具有写入权限。pipe head+1 - step Ⅴ:利用
write向管道中写入恶意数据,因为上一个pipe_buffer没有写满,从而将数据拷贝到上一个pipe_buffer对应的页面——即文件映射的页面。完成越权写入
0x04:漏洞利用
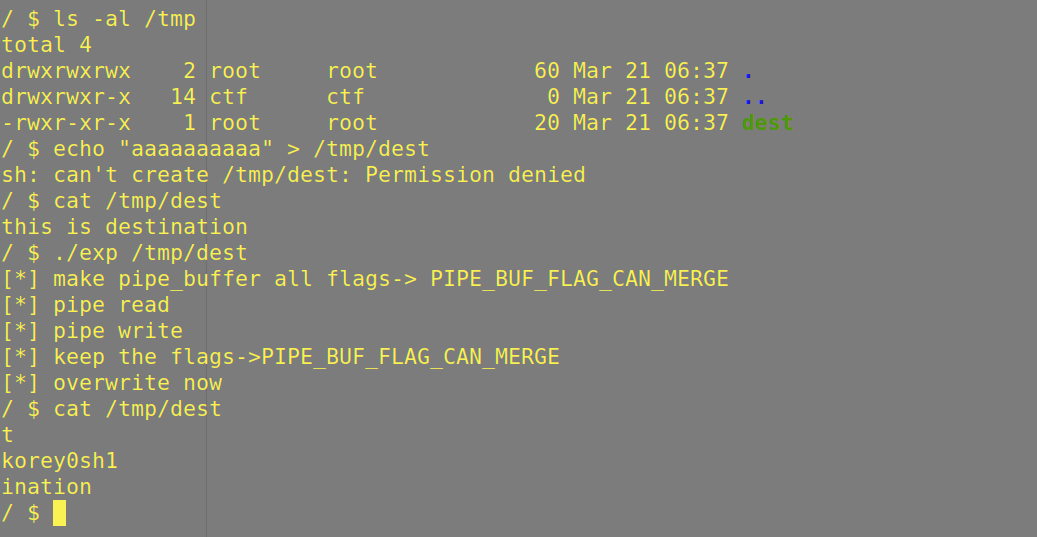
demo
经过上述分析利用demo就很好写了
1 | |
随便用qemu起了个环境,kernel version = 5.8
效果还是很成功的
提权
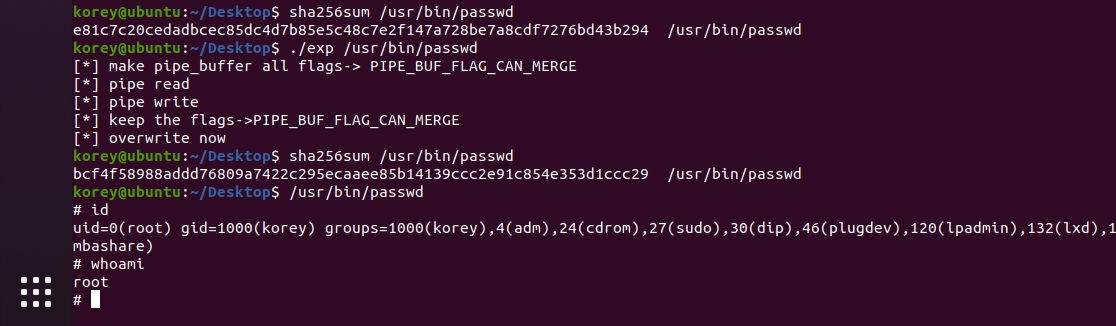
常规的suid提权方式
查看具有root权限的suid文件
1 | |
此处还是选择老朋友/usr/bin/passwd
用msf生成提权的shellcode
1 | |
final exp
1 | |
环境:

运行效果
some tricks
笔者在最后一直苦于找不到合适的kernel版本的虚拟机呜呜呜呜呜,因为下了个挺古早版本的ubuntu20,觉得应该能符合版本要求
结果玩意会自动更新,下下来漏洞都是被patch的
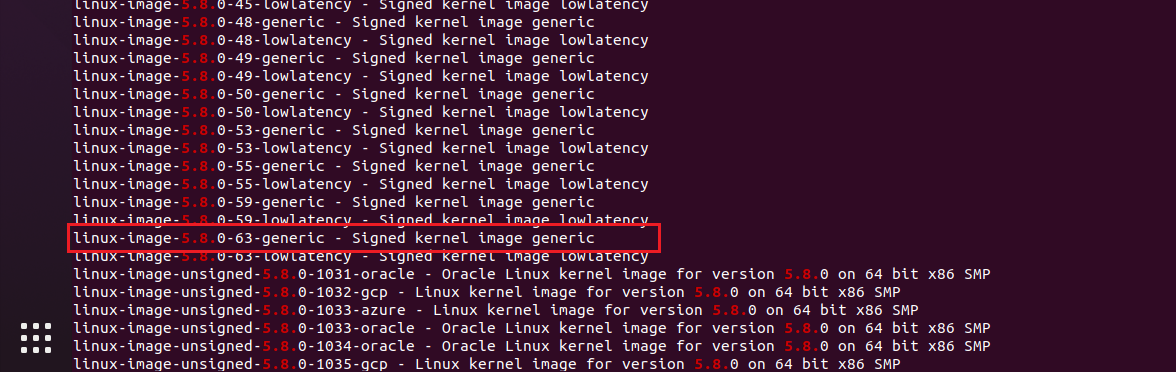
最后发现了xi@0ji233 的文章,了解到了一种十分方便快捷的更换kernel版本的方法
首先先用apt寻找一下这个版本
1 | |
选择这个
下载
1 | |
接下来更改grub启动项
1 | |
改成这样
1 | |
更新grub
1 | |
reboot重启后狂按SHIFT+TAB进入引导模式,选择高级设置,选择新下载的内核版本,即可完成环境搭建
0xff:写在最后的最后
The Dirty Pipe Vulnerability — The Dirty Pipe Vulnerability documentation (cm4all.com)
拜读完漏洞发现者的博客,敬佩他居然能从一次小小的CRC校验错误入手,深挖近一年时间,挖掘原本并不熟悉的Linux Kernel,
并最终发现了Dirty Pipe这一威力巨大的内核0day
作者的探索精神,值得笔者学习
路漫漫其修远兮,吾将上下而求索